A Byte of Blockchain - Week 29 Chains & Forks - Nakamoto Consensus

Recap
Last week we defined Blockchain protocols as a set of underlying rules that define the logic & functioning of a blockchain.
Protocols are rules based on the code underlying the platform on how everything gets done in a blockchain just like there are processes, policies, laws & regulations governing the functioning of the financial services sector.
Protocols are what guides the nodes in their functional responsibilities of validating transactions, mining, validating, adding blocks etc.
Selecting the right chain
In week 25 (Verification & Addition of blocks), we asked
Is there only one chain in a blockchain?

Take a moment to go through the visualization above. When we try to access a blockchain, this is what it looks like. It's a network of computers scattered all over the globe connected to each other through the internet.
In traditional finance, a transaction goes through input and authorization stage. Thus, resources, time and effort goes into verifying the authenticity of a transaction from initiation to booking the transaction into the ledger.
We can be sure that the transaction is authentic and verified because
- There are checks by staff at the input stage for accuracy and authentication
- There are checks at the authorization stage by a separate staff before booking into the system
If a transaction is booked without any input or verification checks, the authenticity of the transaction itself will be in question & not accepted. Thus, only transactions which have gone through the process of checks & verification during input & authorization are accepted.
We saw in week 25 that once the blocks are validated, they need to be added to the existing blockchain. This is done by linking the new block to the final block in an existing chain using the "previous block hash" field in the block header.
But as we saw above, a blockchain is a decentralized data structure & due to the decentralized nature of blockchain, blocks get propagated to nodes at different times or in other words, all the nodes do not "see" the blocks at the same time. This causes some lag in adding blocks to a chain or different blocks being added (explained below).
This causes the ledger copies to not be in sync and consistent with each other for some time. This means some nodes may not have the same blocks in their respective ledger copies.
How is this inconsistency resolved?
Nakamoto Consensus
The inconsistency of different ledger balances due to blocks arriving at different times is resolved when each node selects and attempts to extend (by adding the new block) the chain of blocks that represents the most Proof of Work done. (Remember our analogy of resources, time and effort in verifying a transaction in traditional finance!!).
Before we go further, one question.. are there multiple chains in a blockchain? How is that possible?
Let us understand two terms -
- Orphans
- Forks
Orphans
What happens when two miners solve the Proof of work algorithm within a very short time of each other? This is a usual situation in any blockchain. When the miners solve the proof of work for their blocks, they immediately "broadcast" their respective blocks to their immediate neighbor nodes who will then propagate them across the network.
Thus, each node that receives these blocks will incorporate them into its blockchain, extending it by one block. Let us visualize it as below :
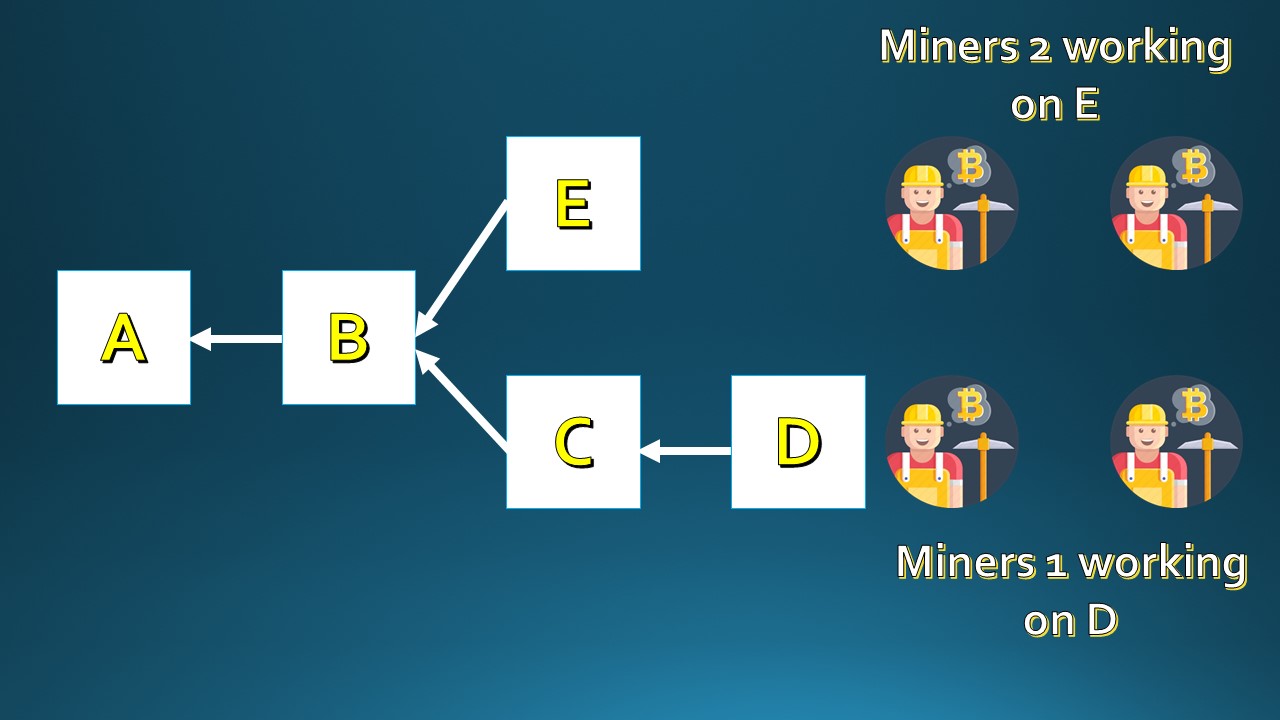
A pool of miners (let us call them Miners 1) are working on block D and another pool of miners (let us call them Miners 2) are working on block E.
They both solve the proof of work at almost the same time and propagate their respective blocks into the network. This creates a conflict amongst the nodes who will add the blocks depending on which block they "see" first.
In our visualization, Block D gets added after Block C and Block E gets added after block B.
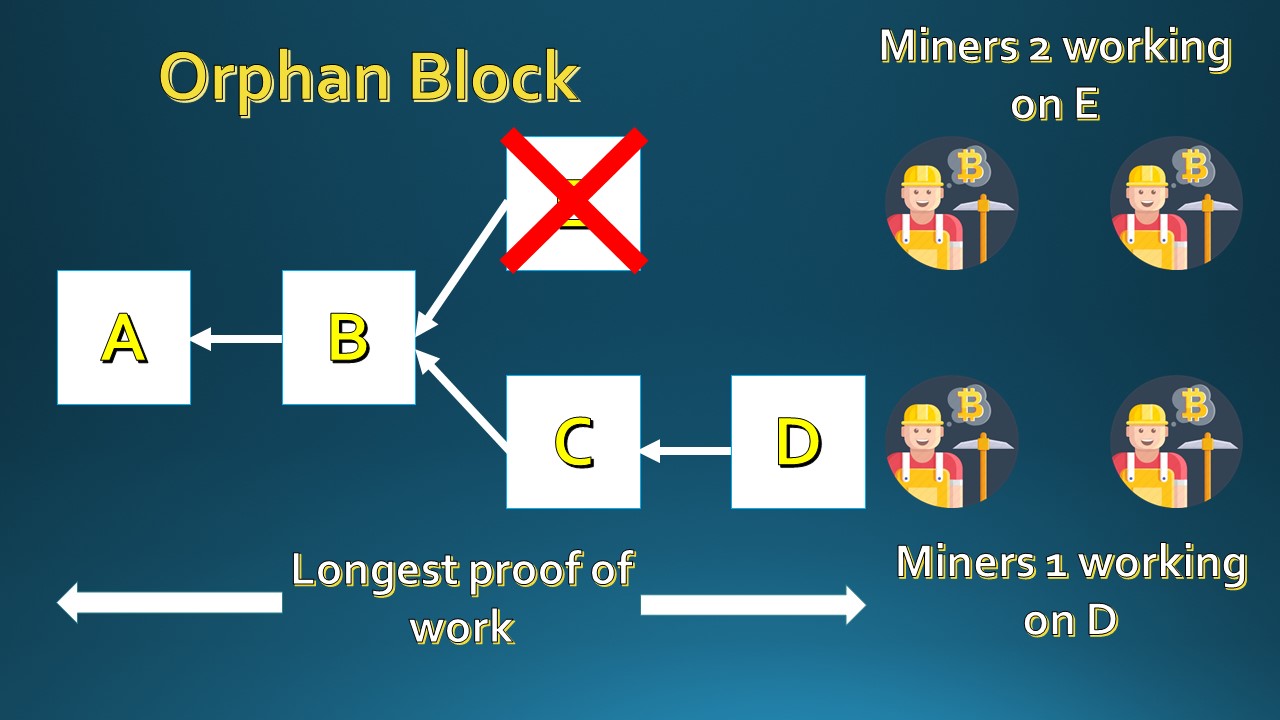
In such a scenario, the block with the larger share of proof of work (The blocks where maximum resources are expended for solving the proof of work) gets accepted by all the nodes ultimately and then the other block will be considered as ORPHAN block and is then discarded.
Once a block is orphaned, all its transactions are sent to the mempool or memory pool from where the transactions are taken to be added to the next block.
In our visualization, Blocks A to C have a larger share of proof of work compared to A & B only to which E was added & ultimately orphaned.
Forks
For a brief moment of time till Block E was made an orphan block, there were two chains
- A - B - E
- A - B - C - D
Some miners work on the first chain which from their perspective is the correct one and try to extend that chain while some other miners work on the second chain and try to extend that chain.
This is when a "fork" occurs whenever there are two chains competing to form the longest one. Why longest one? Because the longest chain has the most proof of work done. This occurs whenever two miners solve the Proof of work algorithm within a short period of time of each other.
Ultimately all the nodes will "see" the longest chain which underwent most Proof-of-Work and re-converge to that chain with the block in the other chain becoming an orphan as mentioned above.
This is also known as the longest - chain rule or Nakamoto Consensus.
Nakamoto Consensus is a consensus mechanism that states that the valid chain is the longest chain with the most accumulated Proof-of-Work. (Source : here)




